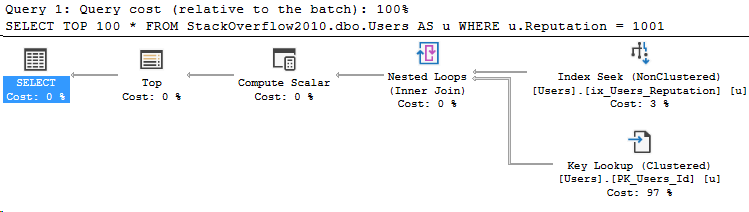
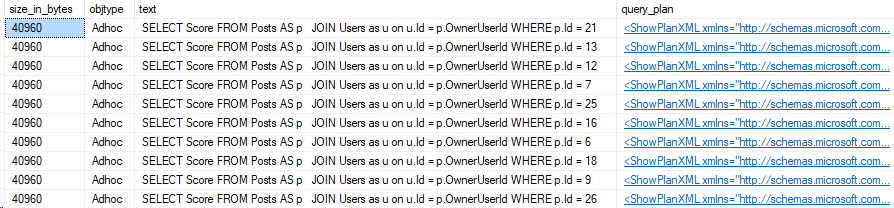
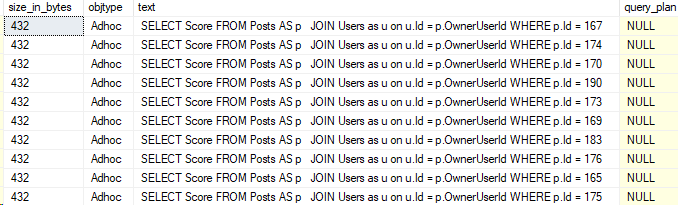
Cosmos DB has become my latest focus and I hope to start sharing more about ways you can use it. Cosmos DB doesn’t provide the same granularity of query plans as you can get in SQL Server, but it actually does provide some super useful data in the Portal and in Log Analytics.
The first thing to know about Cosmos DB is that everything is measured in Request Units (RU). RUs are a measure of CPU, memory, and disk to perform the operation and return the document. Please especially make note of the second part of that. If you return a lot of documents or exceptionally large documents, your RU charges will be high.
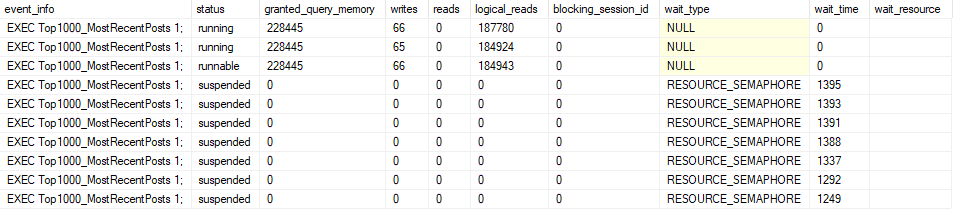
Queries, reads, inserts, updates, and deletes can all be measured by the RUs necessary to complete the action. This means that you want to keep track of the Request Charge value in our queries. The other metric that’s important to track is the Server-Side Latency. There should usually be a correlation between RU charge and Server-Side Latency of the request.
What’s next?
Now that you know the basics of a request charge, we need to get into Metrics and Diagnostic Settings. The default aggregation is usually Average or Sum but I like to start by measuring the Max of Total Request Units in the Metrics tab. Then add in splitting by the Operation Type and filter or split by the Collection and Database. Combining these metrics will give you a great idea of the largest requests sent to Cosmos DB and what type.
Once we have that view, we’re looking for any exceptional activities. Things like a 10,000 RU Query or a 5,000 RU Upsert would certainly be worth investigating. Once you have an idea of where to look by using these Metrics, we will really need Diagnostic Settings. There’s a charge to collecting Diagnostic Settings and they have to be enabled (before the issue occurred so you have data on that issue), but once you have that data, you’re in a great position to start analyzing any issues.
If you’re using the NoSQL API, start by using the the example queries on this page. Just remember that when you include CDBQueryRuntimeStatistics, you will be limited to just queries and not inserts/writes/upserts/etc. To get that data, only use CDBDataPlaneRequests.
For further reading:
https://devblogs.microsoft.com/cosmosdb/cost-optimized-metrics-through-log-analytics/
Hope this was useful! In a future post, I’d like to dive deeper into how you can performance tune a high RU request. Stay tuned!