Query Store Internals: Indexes on the system views
Foreword
The Query Store is a great new feature available starting in SQL Server 2016. I started using it a few months ago, and learned a lot about it from Erin Stellato (blog | twitter)! I got a chance to speak with her at SQL Saturday Cleveland, where we discussed the indexes in this post. Thank you Erin for all your help with this post and understanding the Query Store! To anyone reading this post who wants to learn more, I highly recommend Erin’s blog posts and Pluralsight courses on Query Store.
Structure of the Query Store
The easiest way to see what’s stored in the Query Store is to query the catalog views. Behind the scenes of catalog views, data is stored in system tables . There are many benefits to this, starting with the fact that your performance data will survive a reboot. If we want to see these tables, we can search for them by looking for clustered indexes or heaps, that store this data. But when we query for these tables or their indexes, nothing shows up:
(Query taken from Microsoft’s documentation on sys.indexes)
SELECT i.name AS index_name
,COL_NAME(ic.object_id,ic.column_id) AS column_name
,ic.index_column_id
,ic.key_ordinal
,ic.is_included_column
FROM sys.indexes AS i
INNER JOIN sys.index_columns AS ic
ON i.object_id = ic.object_id AND i.index_id = ic.index_id
WHERE i.name like ‘%query_store%’
order by i.name

Another approach
Let’s try looking for just one view. Here’s a query store catalog view-:
sys.query_store_runtime_stats (and more from Microsoft)
Same query, different keyword:
SELECT i.name AS index_name
,COL_NAME(ic.object_id,ic.column_id) AS column_name
,ic.index_column_id
,ic.key_ordinal
,ic.is_included_column
FROM sys.indexes AS i
INNER JOIN sys.index_columns AS ic
ON i.object_id = ic.object_id AND i.index_id = ic.index_id
WHERE i.name like ‘%runtime%’
order by i.name
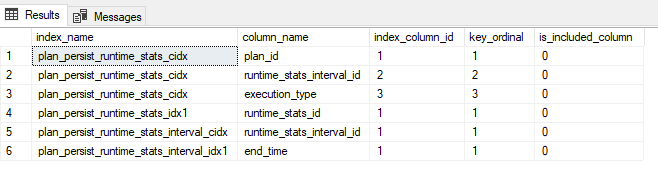
Now we’re talking!
It looks like internally Query Store is referred to as plan_persist. That makes sense, thinking about how the Query Store persists query plans to your database’s storage. Let’s take a look at those catalog views vs their clustered and nonclustered indexes. I’ve modified the query a bit at this point, to group together the key columns.
SELECT i.name AS index_name ,
CASE when i.index_id = 1 THEN ‘Clustered’
WHEN i.index_id = 0 THEN ‘Heap’
ELSE ‘Nonclustered’ END as TypeOfIndex,
STUFF((
SELECT ‘,’ + COL_NAME(ic.object_id,ic.column_id)
FROM sys.index_columns as ic
WHERE i.object_id = ic.object_id AND i.index_id = ic.index_id
and is_included_column = 0 FOR XML PATH(”)),1,1,”)
AS [KeyColumns]
FROM sys.indexes AS i
WHERE i.name like ‘%plan_persist%’
Results:
| Catalog View Name |
Index Name |
Key Columns |
Type of Index |
| sys.query_store_query_text (Transact-SQL) |
plan_persist_query_text_cidx |
query_text_id |
Clustered |
| sys.query_store_query (Transact-SQL) |
plan_persist_query_cidx |
query_id |
Clustered |
| sys.query_store_plan (Transact-SQL) |
plan_persist_plan_cidx |
plan_id |
Clustered |
| sys.query_store_runtime_stats (Transact-SQL) |
plan_persist_runtime_stats_cidx |
plan_id,runtime_stats_interval_id,execution_type |
Clustered |
| sys.query_store_runtime_stats_interval (Transact-SQL) |
plan_persist_runtime_stats_interval_cidx |
runtime_stats_interval_id |
Clustered |
| sys.query_context_settings (Transact-SQL) |
plan_persist_context_settings_cidx |
context_settings_id |
Clustered |
| Undocumented |
plan_persist_query_hints_cidx |
query_hint_id |
Clustered |
| Undocumented |
plan_persist_query_template_parameterization_cidx |
query_template_id |
Clustered |
| sys.query_store_wait_stats (Transact-SQL) |
plan_persist_wait_stats_cidx |
runtime_stats_interval_id,plan_id,wait_category,execution_type |
Clustered |
|
plan_persist_query_text_idx1 |
statement_sql_handle |
Nonclustered |
|
plan_persist_query_idx1 |
query_text_id,context_settings_id |
Nonclustered |
|
plan_persist_plan_idx1 |
query_id |
Nonclustered |
|
plan_persist_runtime_stats_idx1 |
runtime_stats_id |
Nonclustered |
|
plan_persist_runtime_stats_interval_idx1 |
end_time |
Nonclustered |
|
plan_persist_query_hints_idx1 |
query_hint_id |
Nonclustered |
|
plan_persist_query_template_parameterization_idx1 |
query_template_hash |
Nonclustered |
|
plan_persist_wait_stats_idx1 |
wait_stats_id |
Nonclustered |
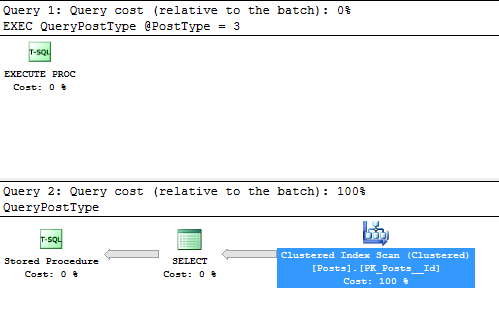
Knowing this, we can query the Query Store using predicates supported by indexes! We can also see the Query Store indexes if we request actual Execution Plans.
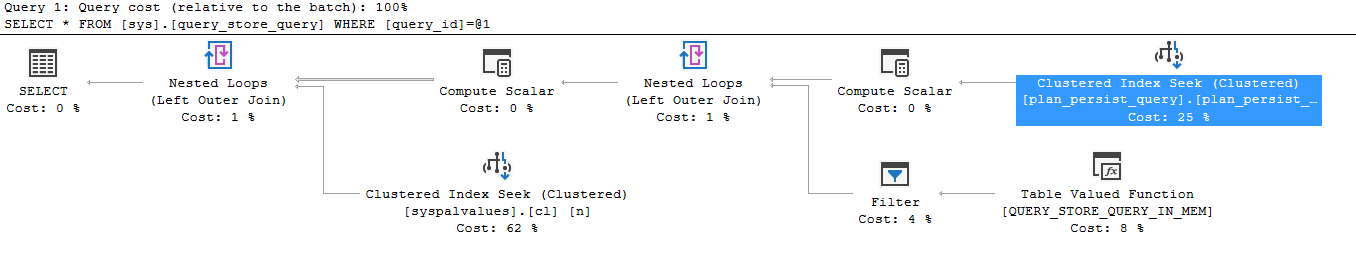
Here’s my query:
select * from sys.query_store_query
where query_id = 5
Here’s the execution plan:
And here’s the predicate that was applied:
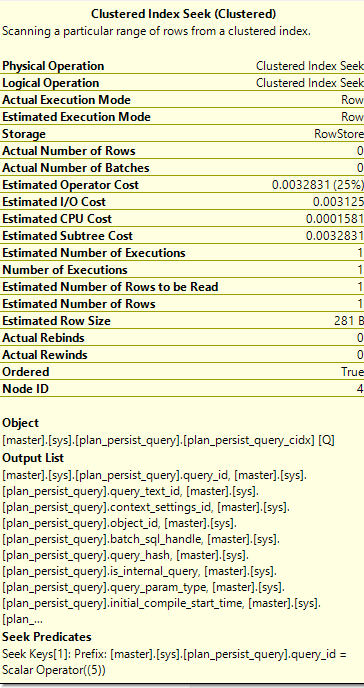
Looking at this execution plan, the object is “plan_presist_query_cidx”, which is the index from above. This shows that Query Store uses these “plan persist” indexes, as the indexes behind the catalog views.
So what’s the point?
Well, Query Store size is user defined, so we can control how much space is consumed by the data in total. As our Query Store gets bigger, queries against the Query Store tables will start running slower unless we use the indexes properly. It’s important to know these indexes if you’re going to be querying Query Store regularly.
Final note (don’t do this in production)
As a cool side note, it’s possible to query the system tables directly if you’re connected to a SQL Server using the Dedicated Admin Connection (DAC). Please use only use the DAC on a test or local server for this example:
The connection prefix, “ADMIN:” shows that I’m connected with the DAC.