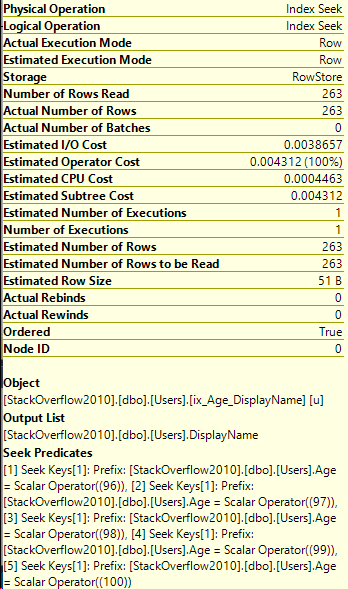
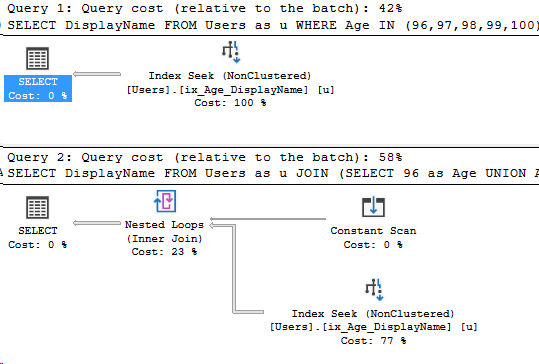
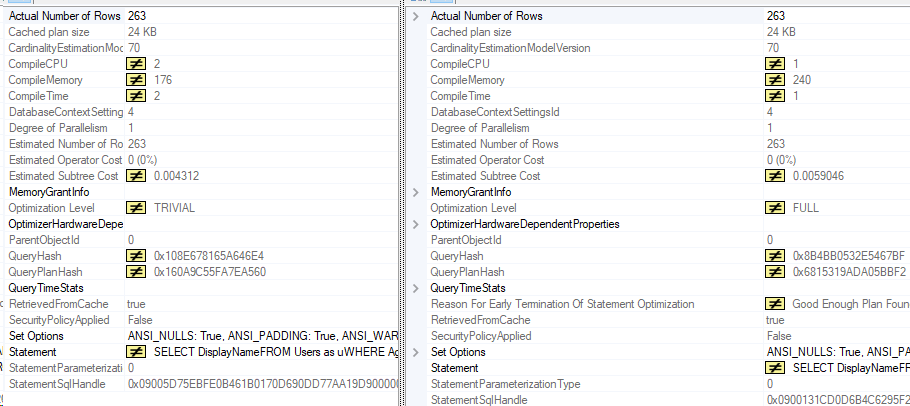
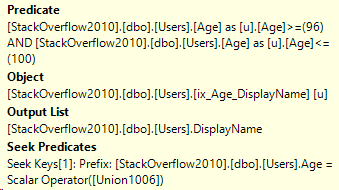
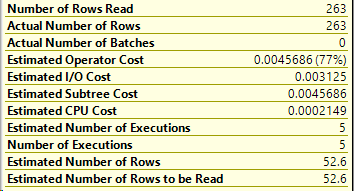
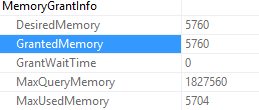
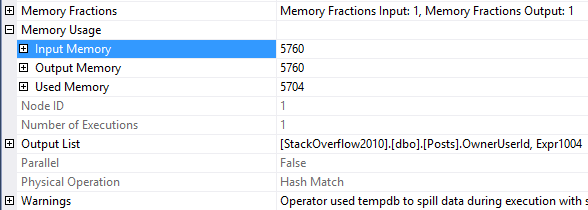
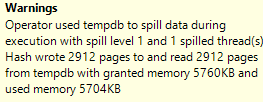
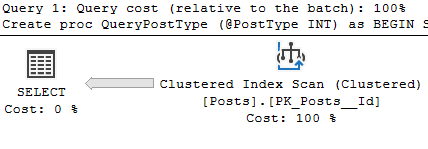
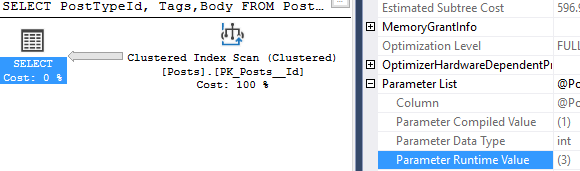
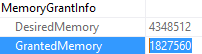
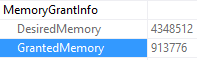
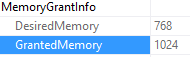
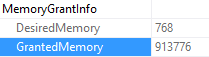
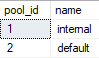
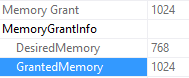
It depends on where you’re looking and how many statements are in the stored procedure.
Let’s take a look at some demos!
First, let’s create a stored procedure with multiple statements
USE StackOverflow2010
GO
CREATE OR ALTER PROCEDURE TestStatements (@Username NVARCHAR(100)) AS
BEGIN
SELECT Reputation FROM Users
WHERE DisplayName = @Username
SELECT DownVotes FROM Users
WHERE DisplayName = @Username
END
GOGreat! Now, I’ll execute the procedure.
--Clear your plan cache for this demo
EXEC TestStatements 'Arthur'
GO 10Perfect. I ran it 10 times to ensure the plan stays in cache for my other demos. Now, my favorite plan cache view is sys dm_exec_query_stats since it has the statistics on usage.
SELECT
s_text.text,
s.creation_time,
s.last_execution_time,
s.execution_count,
s.statement_sql_handle
FROM sys.dm_exec_query_stats as s
CROSS APPLY sys.dm_exec_sql_text(s.sql_handle) as s_text
So we have two entries for this stored procedure. I included the statement sql handle to show that each statement handle has its own text. Let’s parse that text to see each statement. I copied the parsing SQL from this Plan Cache article.
SELECT
SUBSTRING(text, (statement_start_offset/2) + 1,
((CASE statement_end_offset
WHEN -1
THEN DATALENGTH(text)
ELSE statement_end_offset
END - statement_start_offset)/2) + 1) AS query_text,
s.creation_time,
s.last_execution_time,
s.execution_count
FROM sys.dm_exec_query_stats as s
CROSS APPLY sys.dm_exec_sql_text(s.sql_handle) as s_text
So there’s one entry per statement inside sys dm_exec_query_stats. Let’s take a look at another plan cache DMV, dm_exec_cached_plans.
select
s_text.text,
s.cacheobjtype,
s.objtype from sys.dm_exec_cached_plans as s
CROSS APPLY sys.dm_exec_sql_text(s.plan_handle) as s_text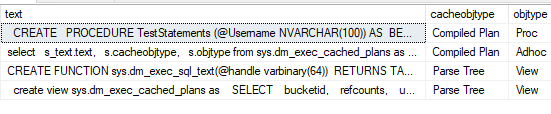
In this view, only the top entry is for the stored procedure. In my opinion, this brings us to a total of three objects in the plan cache for this stored procedure.
I’ll make another post about clearing stored procedures from the plan cache! Thanks for reading, stay tuned!