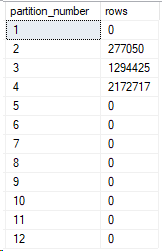
So, we’ve set up a table with table partitioning on the RIGHT for CreationDate. We defined 11 partitions, and in Partitioning 4, we saw 11 partitions. However, if we look in sys partitions, there’s actually 12.
SELECT
p.partition_number,
p.rows
FROM sys.partitions AS p
JOIN sys.tables AS t ON t.object_id = p.object_id
WHERE t.name = 'Posts_Partitioned'
AND p.index_id = 1;
What does this mystery partition contain?
Well, in Partition 2, I queried for the values in the 3rd partition. That was from the start to end of 2009. Let’s take a quick look at the partition function I created.
CREATE PARTITION FUNCTION Posts_Partition_Function (DATETIME)
AS RANGE RIGHT FOR VALUES ('2008-01-01',
'2009-01-01',
'2010-01-01',
'2011-01-01',
'2012-01-01',
'2013-01-01',
'2014-01-01',
'2015-01-01',
'2016-01-01',
'2017-01-01',
'2018-01-01') ; --This is the 11th partition
GO
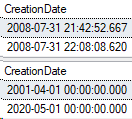
Let’s change some data and see what sys partitions shows for row count.
SELECT CreationDate
FROM Posts_Partitioned
WHERE Id IN (1,2);
GO
UPDATE Posts_Partitioned
SET CreationDate = '2001-04-01'
WHERE Id = 1;
UPDATE Posts_Partitioned
SET CreationDate = '2020-05-01'
WHERE Id = 2;
GO
SELECT CreationDate
FROM Posts_Partitioned
WHERE Id IN (1,2);
GO
And here’s the results:
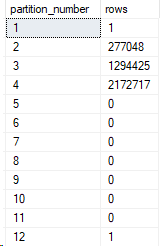
Great! Now back to the sys partitions query from above.
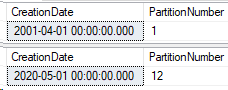
Now there’s data in both partition 1 and 12. Let’s query by partition function and see what data is inside those partitions.
SELECT CreationDate,
$PARTITION.Posts_Partition_Function(CreationDate) AS PartitionNumber
FROM Posts_Partitioned AS p
WHERE $PARTITION.Posts_Partition_Function(CreationDate) = 1;
GO
SELECT CreationDate,
$PARTITION.Posts_Partition_Function(CreationDate) AS PartitionNumber
FROM Posts_Partitioned AS p
WHERE $PARTITION.Posts_Partition_Function(CreationDate) = 12;
GO
What happened to the extra partition?
Well, data that falls outside the range of the last partition on the right side will go into the last partition for my range right partitioning function. This is handy in case bad data is input into your system or your partition maintenance jobs haven’t created enough partitions.
Hopefully this throws up warning signs about either the source of the bad data or the lack of extra partitions.
Happy Friday! Today’s post will be light on the performance side and instead, I’m going to talk about how to take a look at your server’s partitioning.
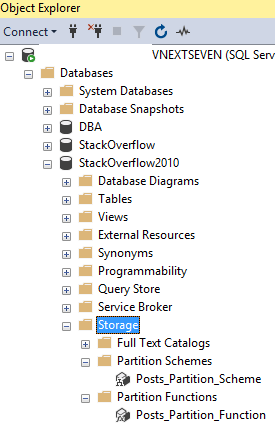
First, partitioning in SQL Server Management Studio
Object Explorer, that thing on the left side of the SSMS window, will show partition info. However, since partitioning is database-level, you’ll have to go to each database.
In your database, go to Storage, then to Partition Schemes or Partition Functions:
When I first started working on tables with partitioning, I kept expecting partitioning to be in “Programmability” with stored procedures and other programming functions. However, since partitioning is a storage feature, it makes sense to me that it’s stored here.
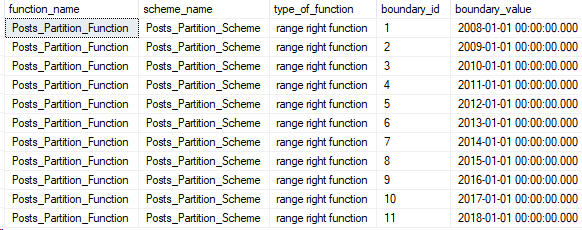
What about querying for all partition functions and schemes?
There’s several DMVs to find information on partitions. Since it’s Friday, I’ll just post my query and show you what the partition functions and schemes on my database look like:
USE StackOverflow2010
GO
SELECT
functions.name AS function_name,
schemes.name AS scheme_name,
CASE WHEN boundary_value_on_right = 1
THEN 'range right function'
ELSE 'range left function' END
AS type_of_function,
val.boundary_id,
val.value as boundary_value
FROM sys.partition_range_values AS val
JOIN sys.partition_functions AS functions
ON val.function_id = functions.function_id
JOIN sys.partition_schemes AS schemes
ON schemes.function_id = schemes.function_id
ORDER BY functions.name, boundary_id
Alright, that’s it! Keep in mind that partition functions and schemes are database-specific, so modify the query or run it in each of the databases you want to check. Stay tuned!
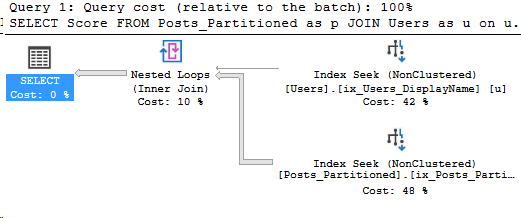
In Partitioning 2, I showed how to analyze which partitions were accessed by our Index Seek. However, we were searching the entire year’s partition for data. What if we filtered more specifically on the partitioning key?
Yesterday’s query: redux
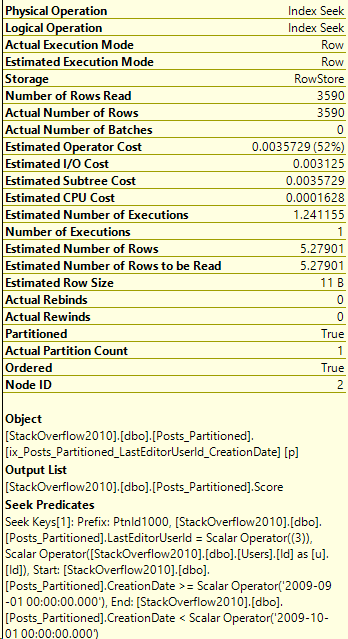
Taking the same query, but this time let’s just search for a single month of CreationDates. In part 2, the query for the entire year read 130 pages of the Posts table, and now we just want September:
SET STATISTICS IO ON;
SELECT Score FROM Posts_Partitioned as p
JOIN Users as u on u.Id = p.LastEditorUserId
WHERE u.DisplayName = 'Community'
AND p.CreationDate >= '2009-09-01' and p.CreationDate < '2009-10-01'
/*
(3590 rows affected)
Table 'Posts_Partitioned'. Scan count 1, logical reads 130,
physical reads 0, read-ahead reads 0, lob logical reads 0,
lob physical reads 0, lob read-ahead reads 0.
Table 'Users'. Scan count 1, logical reads 3, physical reads 0,
read-ahead reads 0, lob logical reads 0, lob physical reads 0,
lob read-ahead reads 0.
*/
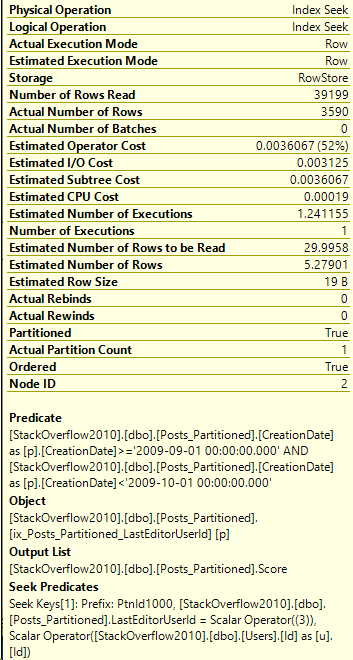
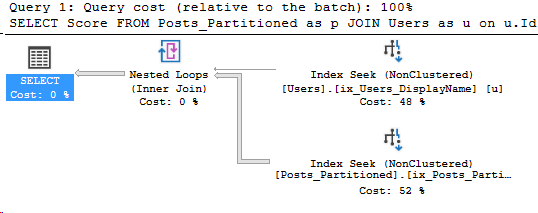
Here’s the execution plan for the new query as well:
Details on the Posts_Partitioned Index Seek:
It’s a very similar execution plan, and the query looks fast. However, even though it returned less rows than the query in Partitioning 2, it still read the same amount of pages, 130.
Index design
At this point, we need to look at the index design. The index being used is defined as:
CREATE NONCLUSTERED INDEX ix_Posts_Partitioned_LastEditorUserId
ON Posts_Partitioned(LastEditorUserId)
INCLUDE (Score)
ON Posts_Partition_Scheme(CreationDate)
GO
So, let’s try changing the keys to see if we can get a better execution plan. First, let’s add CreationDate to the keys.
CREATE NONCLUSTERED INDEX ix_Posts_Partitioned_LastEditorUserId_CreationDate
ON Posts_Partitioned(LastEditorUserId,CreationDate)
INCLUDE (Score)
ON Posts_Partition_Scheme(CreationDate)
GO
And re-running our query:
SET STATISTICS IO ON;
SELECT Score FROM Posts_Partitioned as p
JOIN Users as u on u.Id = p.LastEditorUserId
WHERE u.DisplayName = 'Community'
AND p.CreationDate >= '2009-09-01' and p.CreationDate < '2009-10-01'
/*
(3590 rows affected)
Table 'Posts_Partitioned'. Scan count 1, logical reads 16,
physical reads 0, read-ahead reads 0, lob logical reads 0,
lob physical reads 0, lob read-ahead reads 0.
Table 'Users'. Scan count 1, logical reads 3, physical reads 0,
read-ahead reads 0, lob logical reads 0, lob physical reads 0,
lob read-ahead reads 0.
*/
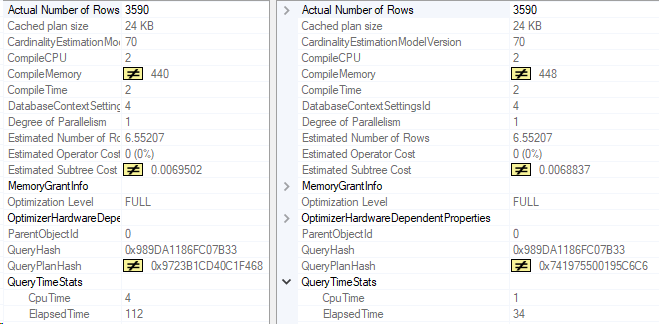
That’s a lot better! And here’s the index seek’s information:
Click image for better quality
Even better. Let’s compare these two execution plans. The left side is with the original index, the right side is after, with the CreationDate key added.
What’s the moral of this post?
The point I want to make is that post-partitioning, you may have to re-think some of your existing indexes. Even if you add the partitioning key to all your queries, that can change your workload enough that you’ll want to examine your indexes.
Stay tuned!
P.S. What if we put CreationDate as the first key in the index?
I’ll drop the index used in this example, and create an index with CreationDate as the first key column.
DROP INDEX ix_Posts_Partitioned_LastEditorUserId_CreationDate
ON Posts_Partitioned
GO
DROP INDEX ix_Posts_Partitioned_LastEditorUserId
ON Posts_Partitioned
GO
CREATE NONCLUSTERED INDEX ix_Posts_Partitioned_CreationDate_LastEditorUser
ON Posts_Partitioned(CreationDate,LastEditorUserId)
INCLUDE (Score)
ON Posts_Partition_Scheme(CreationDate)
GO
And now we re-run the query from above. Let’s take a look at the stats and the execution plan:
In Partitioning 1, my query searched through all 1-12 partitions. Let’s see if we can reduce that number.
Adding the partitioning key to your query
Since I created the index in part 1 on the Posts_Partition_Scheme, the index was split up among the partitions. What if I only want to search data, let’s say in 2009? Well, in that case, we should add it to our query!
In part 1, I defined the table with a RIGHT partitioning function on the column CreationDate, with one partition per year.
SET STATISTICS IO ON;
SELECT Score FROM Posts_Partitioned as p
JOIN Users as u on u.Id = p.LastEditorUserId
WHERE u.DisplayName = 'Community'
AND p.CreationDate >= '2009-01-01' and p.CreationDate < '2010-01-01'
/*
(39199 rows affected)
Table 'Posts_Partitioned'. Scan count 1, logical reads 130,
physical reads 0, read-ahead reads 0,
lob logical reads 0, lob physical reads 0,
lob read-ahead reads 0.
Table 'Users'. Scan count 1, logical reads 3,
physical reads 0, read-ahead reads 0,
lob logical reads 0, lob physical reads 0,
lob read-ahead reads 0.
*/
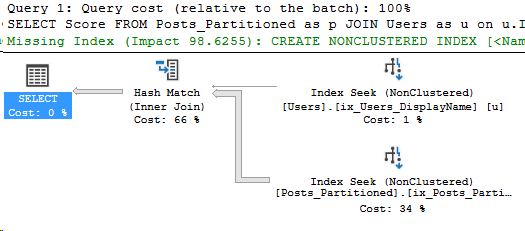
The total is 130 logical pages read, not bad! Let’s take a look at the execution plan.
And I’ll focus on the Index Seek for Posts_Partitioned:
Click the image for better quality
Hmm, while this execution plan looks good, since there’s a non-Seek predicate on CreationDate, it might also be worthwhile to add the partitioning key to my index. Stay tuned for more posts in this series where I’ll talk about improving this index!
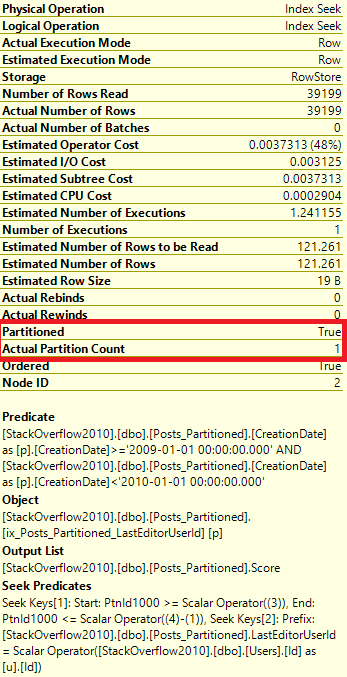
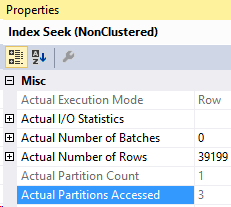
For now, let’s focus on the Actual Partition Count value. In the example in Part 1, the query used all 12 partitions. Now the query only accessed one partition.
Which partition was accessed?
Well, to find which partition was accessed, let’s look at the Properties of the Index Seek from above.
Ah, so it accessed partition #3! Now, since we created this partition function recently, we know that’s 2009. But what if we didn’t know that?
Finding min and max values in a partition
Here’s a query I wrote for Posts_Partitioned to get the min and max values for my partition function, based on $PARTITION.
SELECT
MIN(CreationDate) as Min_CreationDate,
MAX(CreationDate) as Max_CreationDate
FROM Posts_Partitioned as p
WHERE $PARTITION.Posts_Partition_Function(CreationDate) = 3
GO
Query results:
As we might expect, both values fall within 2009.
Okay, that’s it for this post! I wanted to show how you could achieve and measure partition elimination in a specific query. I want to fix that index from earlier and talk more about partitions later.
Here’s my take on partitioning. I’ll be focusing on getting queries to perform on partitioned tables, and not on partition maintenance, which can be its own headache. This is the first part in a series I’m planning to write, so this post may not answer all the questions.
Partitioning disclaimer
I feel like it’s necessary to add a disclaimer: Partitioning is not designed as a performance feature, its strengths are in moving large amounts of data in a single command. Truncating an entire partition is also an easy way to delete stale data without using a lot of space in the transaction log.
Setting up a partitioned table
CREATE PARTITION FUNCTION Posts_Partition_Function (DATETIME)
AS RANGE RIGHT FOR VALUES ('2008-01-01',
'2009-01-01',
'2010-01-01',
'2011-01-01',
'2012-01-01',
'2013-01-01',
'2014-01-01',
'2015-01-01',
'2016-01-01',
'2017-01-01',
'2018-01-01') ;
GO
CREATE PARTITION SCHEME Posts_Partition_Scheme
AS PARTITION Posts_Partition_Function ALL
TO ([PRIMARY]) ;
GO
And creating a Posts_Partitioned table, in StackOverflow2010, to demo the scripts:
USE [StackOverflow2010]
GO
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
IF NOT EXISTS (SELECT * FROM sys.objects WHERE object_id = OBJECT_ID(N'[dbo].[Posts_Partitioned]') AND type in (N'U'))
BEGIN
CREATE TABLE [dbo].[Posts_Partitioned](
[Id] [int] IDENTITY(1,1) NOT NULL,
[AcceptedAnswerId] [int] NULL,
[AnswerCount] [int] NULL,
[Body] [nvarchar](max) NOT NULL,
[ClosedDate] [datetime] NULL,
[CommentCount] [int] NULL,
[CommunityOwnedDate] [datetime] NULL,
[CreationDate] [datetime] NOT NULL,
[FavoriteCount] [int] NULL,
[LastActivityDate] [datetime] NOT NULL,
[LastEditDate] [datetime] NULL,
[LastEditorDisplayName] [nvarchar](40) NULL,
[LastEditorUserId] [int] NULL,
[OwnerUserId] [int] NULL,
[ParentId] [int] NULL,
[PostTypeId] [int] NOT NULL,
[Score] [int] NOT NULL,
[Tags] [nvarchar](150) NULL,
[Title] [nvarchar](250) NULL,
[ViewCount] [int] NOT NULL,
CONSTRAINT [PK_Posts__Id_CreationDate] PRIMARY KEY CLUSTERED
(
[Id], [CreationDate]
)ON [Posts_Partition_Scheme](CreationDate) )
END
GO
Loading some data into Posts_Partitioned
I used the SSIS Import/Export Data Wizard and specified all the columns except the Id column. There’s about 3.7 million rows loaded.
Creating some indexes and comparing performance before and after
Query performance on partitioned tables can be confusing. Yes, queries can run faster on partitioned tables IF they can use partition elimination. That means that the query contained the partitioning column in one of the predicates, like the WHERE clause or the JOIN. Then, the SQL Server optimizer is able to skip those partitions when running the query.
What I’m focusing on is whether a query performs better or worse after partitioning, whether the query is capable of partition elimination, and if it achieved that partition elimination.
First, we’ll create indexes, with the index on Posts_Partitioned aligned to the partition.
CREATE NONCLUSTERED INDEX ix_Posts_LastEditorUserId
ON Posts(LastEditorUserId)
INCLUDE (Score)
GO
CREATE NONCLUSTERED INDEX ix_Users_DisplayName
ON Users(DisplayName)
GO
CREATE NONCLUSTERED INDEX ix_Posts_Partitioned_LastEditorUserId
ON Posts_Partitioned(LastEditorUserId)
INCLUDE (Score)
ON Posts_Partition_Scheme(CreationDate)
GO
Great! Let’s run a query on these tables with our brand new indexes.
SET STATISTICS IO ON;
SELECT Score FROM Posts as p
JOIN Users as u on u.Id = p.LastEditorUserId
WHERE u.DisplayName = 'Community'
--The Community user in StackOverflow is an internal user,
--so it has a lot of posts!
/*
(118119 rows affected)
Table 'Posts'. Scan count 1, logical reads 267,
physical reads 0, read-ahead reads 0,
lob logical reads 0, lob physical reads 0,
lob read-ahead reads 0.
Table 'Users'. Scan count 1, logical reads 3,
physical reads 0, read-ahead reads 0,
lob logical reads 0, lob physical reads 0,
lob read-ahead reads 0.
*/
What about the execution plan?
Looks pretty good to me.
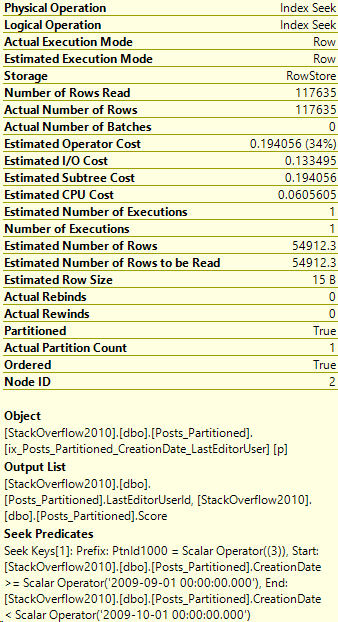
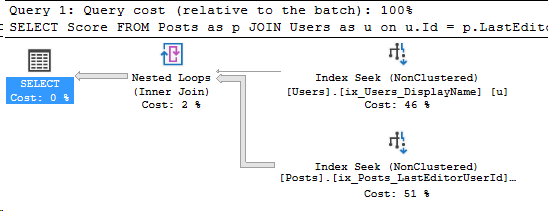
The same query, same indexes on Posts with partition aligned indexes
Uh-oh. This looks a little worse. Just to be sure, let’s look at the execution plan:
So what happened?
The first giveaway is that the query on Posts_Partitioned has a “Scan count” of 12. There’s more answers here though, let’s take a look at the Index Seek.
Here’s the properties of the Index Seek on Posts_Partitioned:
So this Index Seek had to access each partition to check if it had data for our Community user. That increased the amount of work done.
Summary of this example
This is an example of when a query didn’t achieve partition elimination, and therefore it did more work on the partitioned table. I hope to write some other posts on whether this issue could be fixed in the query, and other query patterns that can cause confusion when working with partitioning.
Stay tuned!
By continuing to use the site, you agree to the use of cookies. more information
The cookie settings on this website are set to "allow cookies" to give you the best browsing experience possible. If you continue to use this website without changing your cookie settings or you click "Accept" below then you are consenting to this.