A single use plan is an entry in the SQL Server plan cache that was only used once. When a query generates many similar entries in the plan cache, that query is using extra CPU to generate plans and wasting memory space to store them.
I’m going to focus on finding all single use plans in my plan cache. Then, in a later post, I’ll discuss how to reduce the number of plans.
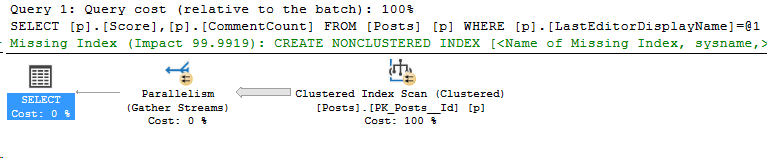
We can find these plans by counting the number of entries in sys dm_exec_query_stats per query hash, where the plan has an execution count of 1.
Here’s a sample script:
SELECT query_hash,
COUNT(*) as number_of_entries
FROM sys.dm_exec_query_stats
WHERE execution_count = 1
GROUP BY query_hash
HAVING COUNT(*) > 1Setting up single use plans
So I want a lot of single use plans. I wrote this SQL in StackOverflow2010 to generate a bunch of queries that will each take up one spot in the plan cache.
SELECT TOP 200
N'EXEC(''SELECT Score FROM Posts AS p
JOIN Users as u ON u.Id = p.OwnerUserId
WHERE p.Id = ' + CAST(Id as nvarchar(200)) + ''')'
FROM Posts
ORDER BY IdRunning those queries on my test server, then running the script above it gives me this result:

So there’s 200 entries in the plan cache for this query. The plan cache can have up to 160,036 entries on 64-bit systems (source), so my test plan cache isn’t in any danger of running out of space.
Looking at the single use plans by query hash
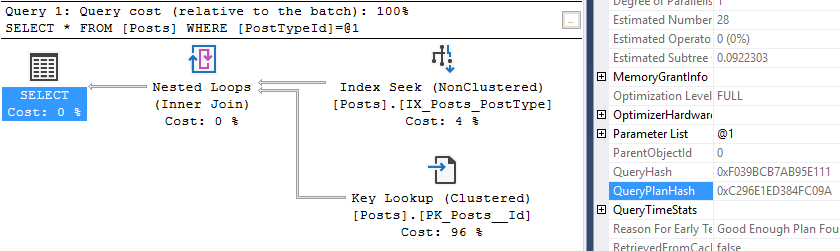
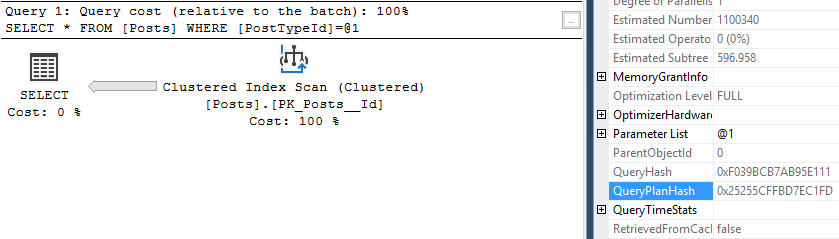
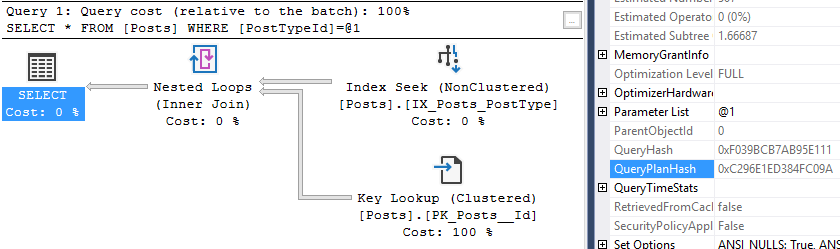
Now let’s take a look at one of those queries. Take the query_hash from above, or one in your environment, and take a look:
SELECT TOP 10 stext.text,
splan.query_plan
FROM sys.dm_exec_query_stats as stat
CROSS APPLY sys.dm_exec_sql_text(stat.sql_handle) as stext
CROSS APPLY sys.dm_exec_query_plan(stat.plan_handle) as splan
WHERE stat.query_hash = 0x5F56B6B5EC1A6A6F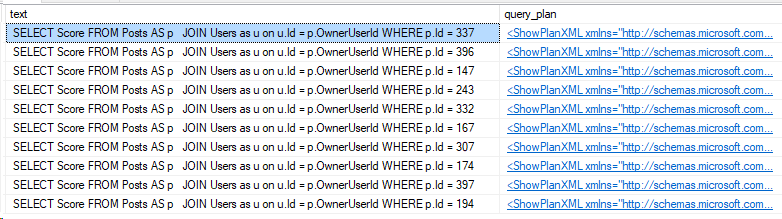
That’s just 10 of the 200 entries in my plan cache which are identical except for the value used in the WHERE clause.
In another post, I’ll tackle ways to handle these duplicates and reduce the number of single plans in cache. Stay tuned!